Prof. Dr. Kurt Braunmüller (Projektleitung)
Dr. Steffen Höder, Dr. Ludger Zeevaert (researchers)
The project was funded by the German Reserarch Foundation as Project H3 (2002–2011) of the Collaborative Research Centre 538 Multilingualism (1999–2011) at the University of Hamburg.
Old Swedish language ausbau in language contact

During the Late Middle Ages, Swedish becomes a written language, and this in a multilingual society where Latin and Low German have a formative influence. At the same time, Swedish in this period undergoes considerable linguistic change. What role does language contact with Latin play in the syntactic development of Old Swedish? How do the communicative conditions of writing affect language change? How do both factors interact? How can this complex linguistic situation be understood from the perspective of modern contact and sociolinguistic models as well as language theory?
These questions were my main field of work in the research project Scandinavian Syntax in Multilingual Contexts (2002–2011) within the Collaborative Research Center 538 Multilingualism at the University of Hamburg. In particular, I investigated the establishment of syntactic innovations in recent Old Swedish. I was mainly concerned with Latin influence on phenomena of clause linking, subordination, word order, relativization, participial constructions, and particle verbs, as well as with the question of whether the innovative features are essentially specific to speaker groups or text types, or whether they depend on the medium and the conception of the texts.
HaCOSSA/PaCMan (corpus of Old Swedish)
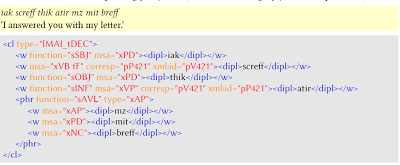
I also worked on building a morphosyntactically annotated digital corpus of (late) Old Swedish texts (The Hamburg Corpus of Old Swedish with Syntactic Annotation, HaCOSSA). In its present form, the corpus contains about 130,000 words. It contains texts from the 13th to the 16th century, with an emphasis on the dominant text type of this period, namely religious prose texts. The corpus is an XML treebank that follows the conventions of the Text Encoding Initiative (TEI) and the Medieval Nordic Text Archive (Menota), as well as its own syntactic annotation scheme (Phrases and Clauses Tagging Manual, PaCMan). Different representations, example searches and quantitative analyses of the corpus are possible by using XPath queries. Starting point for the digital versions of the texts are existing diplomatic editions. The corpus is accessible via the Hamburg Centre for Language Corpora.