Prof. Dr. Kurt Braunmüller (Projektleitung)
Dr. Steffen Höder, Dr. Ludger Zeevaert (wissenschaftliche Mitarbeit)
Das Projekt wurde als Teilprojekt H3 (2002–2011) des Sonderforschungsbereichs 538 Mehrsprachigkeit (1999–2011) an der Universität Hamburg von der Deutschen Forschungsgemeinschaft gefördert.
Altschwedischer Sprachausbau im Sprachkontakt

Das Schwedische wird im Spätmittelalter zur Schriftsprache ausgebaut und zwar in einer mehrsprachigen Gesellschaft, in der Latein und Niederdeutsch einen prägenden Einfluss haben. Zugleich ist im Schwedischen dieser Zeit erheblicher Sprachwandel zu beobachten. Welche Rolle spielt der Sprachkontakt zum Lateinischen für die syntaktische Entwicklung des Altschwedischen? Wie wirken sich die kommunikativen Rahmenbedingungen der Schriftlichkeit im Wandel aus? Wie interagieren beide Faktoren miteinander? Wie lässt sich diese komplexe sprachliche Situation aus der Perspektive moderner kontakt- und soziolinguistischer sowie sprachtheoretischer Modelle erfassen?
Diese Fragen bildeten mein Hauptarbeitsgebiet im Forschungsprojekt Skandinavische Syntax im mehrsprachigen Kontext (2002–2011) innerhalb des Sonderforschungsbereichs 538 Mehrsprachigkeit an der Universität Hamburg. Dabei habe ich die Etablierung syntaktischer Innovationen im jüngeren Altschwedischen untersucht. Es ging besonders um lateinischen Einfluss auf Phänomene der Satzverknüpfung, der Subordination, der Wortstellung, der Relativsatzbildung, der Bildung von Partizipialkonstruktionen und Partikelverben sowie um die Frage, ob die innovativen Merkmale im Wesentlichen gruppen- oder texttypenspezifisch oder von der medial-konzeptionellen Gestaltung der Texte abhängig sind.
HaCOSSA/PaCMan (altschwedisches Korpus)
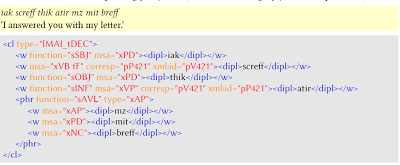
Im Forschungsprojekt Skandinavische Syntax im mehrsprachigen Kontext habe ich mich außerdem mit dem Aufbau eines morphosyntaktisch annotierten digitalen Korpus (spät)altschwedischer Texte beschäftigt (The Hamburg Corpus of Old Swedish with Syntactic Annotation, HaCOSSA). Das Korpus umfasst zurzeit etwa 130.000 Wörter. Es enthält Texte vom 13. bis zum 16. Jahrhundert, mit einem Schwerpunkt auf dem dominanten Texttyp dieser Zeit, nämlich religiösen Prosatexten. Das Korpus stellt eine Treebank im XML-Format dar, die den Konventionen der Text Encoding Initiative (TEI) und des Medieval Nordic Text Archive (Menota) sowie einem eigenen syntaktischen Annotationsschema (Phrases and Clauses Tagging Manual, PaCMan) folgt. Unterschiedliche Darstellungen, Beispielsuchen und quantitative Auswertungen des Korpus sind durch XPath-Abfragen möglich. Ausgangspunkt für die digitalen Versionen der Texte sind bestehende diplomatische Editionen. Das Korpus ist über das Hamburger Zentrum für Sprachkorpora zugänglich.